
The K-NN algorithm is the arguably the simplest machine learning algorithm. Building the model consists only of storing the training dataset. To make a prediction for a new data point, the algorithm finds the closest data points in the training set.
K-Neighbors Classification
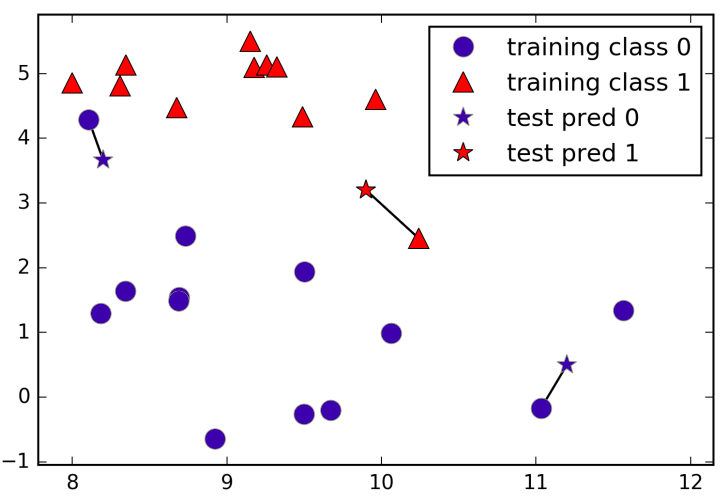
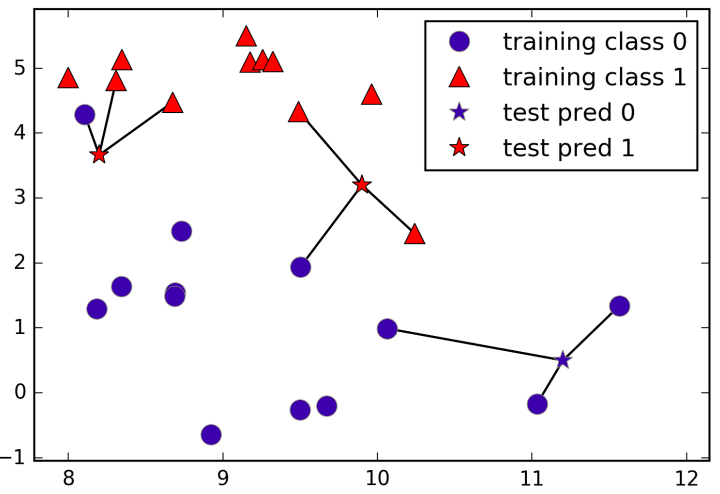
In its simple version, the K-NN algorithm only considers exactly one nearest neighbor, which is the closest training data point to the point we want to make the predicition for. The point that we want to predict will take the label from the nearest neighbor (image 1). Instead of considering only the closest neighbor, we can also consider an arbitrary number, K, of neighbors. When considering more than one neighbor, we use voting to assign a label (image 2).
K-Neighbors Regression
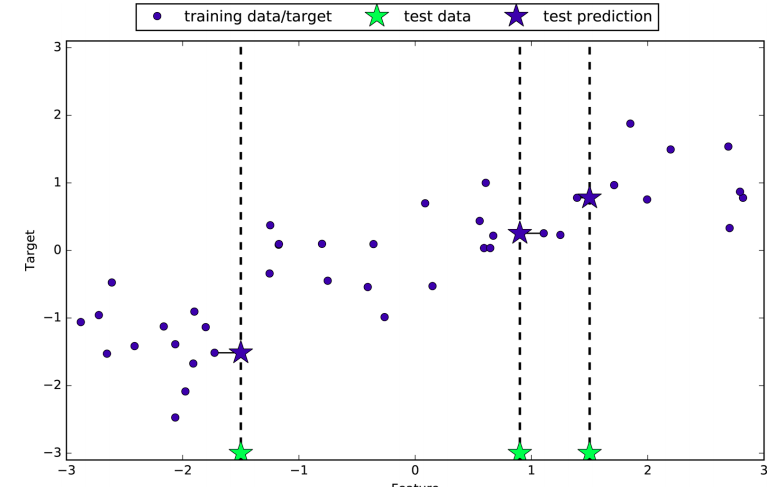
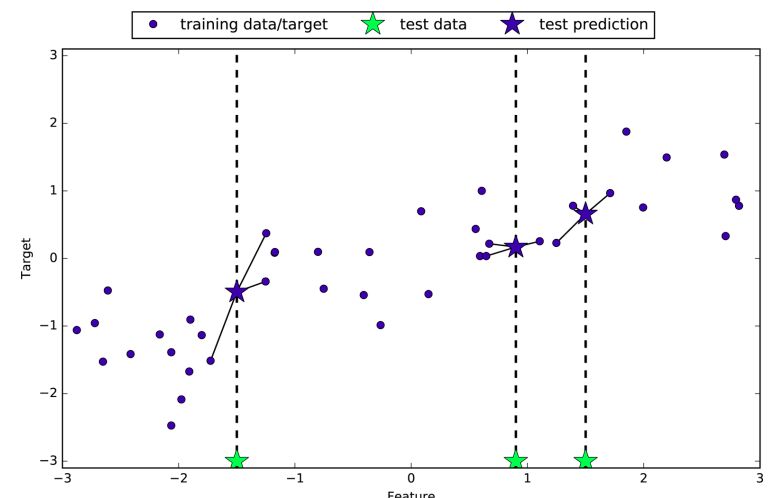
There is also a regression variant of K-nearest neighbors algorithm. The prediction using a single neighbor is just the target value of the nearest neighbor (image 1). Again, we can use more than one neighbor for regression. When using multiple nearest neighbors, the prediction is the average of the relevant neighbors (image 2).
Strenghts, Weaknesses, and Parameters
There are two important parameters to the KNeighbors classifier: the number of neighbors and how to measure distance between points. In practice, using a small number of neighbors increases the complexibility of the model, and using many neighbors corresponds to a much simple model. Considering a single nearest neighbor, the prediction on the training set is perfect. But when more neighbors are considered, the model becomes simpler and the training accuracy drops. The test set accuracy for using a single neighbor is lower than when using more neighbors, indicating that using the single nearest neighbor leads to a model that is too complex. On the other hand, when considering to much neighbors, the model is too simple and performance is even worse. The best performance is somewhere in the middle. By default, Euclidean distance is used, which works well in many situations.
One of the strenghts of K-NN is that the model is very easy to understand, and often gives reasonable performance without a lot of adjustments. Using this algorithm is a good baseline to try before considering more advanced techniques.
Building the nearest neighbors model is usually very fast, but when your training set is very large (either in number of samples or number of features) prediction can be slow. When using the K-NN algorithm, it’s very important to preprocess your data. This approach does not perform well on datasets with many features, and it does particularly badly with data sets where most features are 0 most of the time (so called sparse datasets).